Building a SIEM: centralized logging of all Linux commands with ELK + auditd
Recently, working with the SOC department, we had to enable command logging for more than 10k instances. We also needed to implement a way of parsing those commands and importing them to ELK. Now, if you have researched terminal logging, you’ll know that there are multiple solutions. In this article I’ll explain the one that we choose, why we choose it, and at the end I’ll tell you about a custom rule that it allowed us to write.
The most recommended solution for this problem is using the PROMPT_COMMAND variable in bash which executes before running any command. If you want to go this way, there are great write-ups on how to accomplish it:
https://medium.com/maverislabs/logging-bash-history-cefdce602595
https://spin.atomicobject.com/2016/05/28/log-bash-history/
https://askubuntu.com/questions/93566/how-to-log-all-bash-commands-by-all-users-on-a-server
We, however, chose not to use this solution, as it had some caveats. First, the environmental variable can be reset by the user. In the following example, we set the variable to print a string before any command, and then we unset the variable in order to delete the logging. This would enable any attacker that reads the local ~/.bashrc or /etc/profile to realize that the commands are being logged, and to disable the logging.
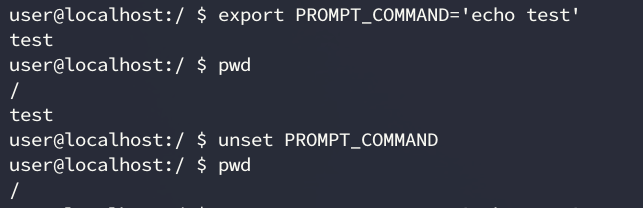
Secondly, depending on which file you use to define the variable, you can bypass this logging feature by just switching the shell. In the following example we change bash for sh, and watch as the variable gets unset automatically. This would allow an attacker to change a definition in, for example, .bashrc.

Each shell sources different files, and you need to have a consistent solution for each and everyone. An attacker might use bash, but he might also use sh, ash, zsh or even dash (lets not forget that some versions of dash, unlike bash, allowed you to start a binary with suid without supplying -p, which is very useful for backdooring a system). The different sourcing of files is also very relevant in cases where you get compromised through an exploited service. When you exploit a service, lets say, apache, you get dropped to a shell without a tty allocation, and you need to contemplate all of the possibilities when defining variables. We wrote a custom rule contemplating this that will be explained at the end.
Thirdly, you can bypass custom regex filters with certain bash features. Say that you want to get notified whenever someone runs an nmap on your network. You would write a regex that identifies any command that has nmap on it. Something like
.*nmap.*This can get easily bypassed, with things like variable expansion / single or double quotes / backslash / aliases:
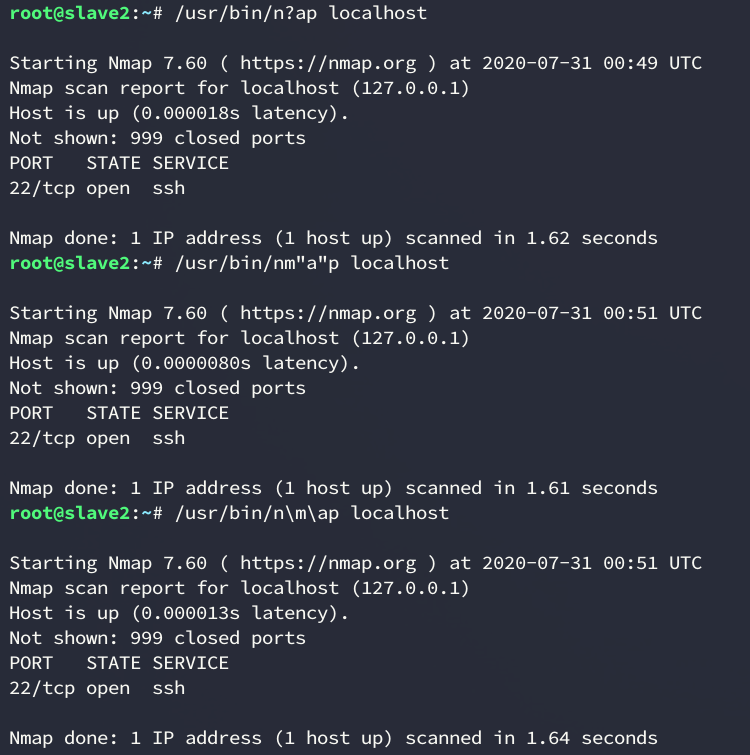
There are multiple ways to achieve this, and if you’re working in a SOC you should probably know all of them. These are a must know when red teaming. You can read more about them here: https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Command%20Injection
Fourthly, you only get commands ran through an interactive console. Any attacker aware of this can create a simple script to run the commands it wants (for example nmap) and those wouldn’t show up in the logfile. Or even worse, compile a simple C script to call the bash command.
We researched a lot of alternative tools (rootsh / pam_tty_audit.so / sudo). I won’t get into the details of these, as this article would end up being miles long, and there are already really detailed write ups about this (https://www.scip.ch/en/?labs.20150604).
We ended up using the auditd service. This is a service that’s tightly integrated with the kernel, and based on all the information that we gathered, its only disadvantage is that it was overly verbose, since it logs at the syscall level. This was actually an advantage for us, since we wanted command logging and not only bash interactive logging. We’ll see in a bit how we took care of the overly verbose aspect with logstash.
Another reason why we chose auditd is that since it is a root level service, its easier to monitor and more difficult to compromise than something like a logfile. Granted, auditd also uses a logfile, but you have a higher privilege service using it that something like a bash process. You can set up custom alerts to notify when a service has been stopped, and contemplate more user cases than what you can do with a file (which can be deleted, changed with an inmutable flag, deleted, emptied, etc…).
Auditd also allows you to log not only the command that the user typed, but the resulting binary invoked (this prevents regex bypass attacks, since you can build the regex to match with the binary instead of the command itself).
In order to implement auditd, you first need to install it:
apt-get install auditd audispd-pluginsAfter that, you’ll need to edit the following file: /etc/auditd/rules.d/audit.rules (on any Debian derivative).
To log all architecture syscalls, you would do the following:
-a always,exit -F arch=b32 -S execve
-a always,exit -F arch=b64 -S execveAfter that, you should enable and start the service:
systemctl enable auditd.service
systemctl start auditd.service You can see the applied rules with:
auditctl -lI’m not gonna get into how to write auditd rules, since the man page will explain it better than I can, but you should know that you can customize the rules with filters. For example, you can enable logging for a single user specifying the effective uid with:
-a always,exit -F arch=b32 -S execve -F euid=0
-a always,exit -F arch=b64 -S execve -F euid=0After enabling auditd, tailing /var/log/audit/audit.log will undoubtedly fill your screen with output:

Don’t worry, we can easily dissect each commands output. Lets run a “whoami” and analyze the output.
type=SYSCALL msg=audit(1596148543.861:63): arch=c000003e syscall=59 success=yes exit=0 a0=565156eecbc0 a1=565156ef1fa0 a2=565156e97ce0 a3=8 items=2 ppid=1667 pid=2806 auid=1000 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=1 comm=”whoami” exe=”/usr/bin/whoami” key=(null)
type=EXECVE msg=audit(1596148543.861:63): argc=1 a0=”whoami”
type=CWD msg=audit(1596148543.861:63): cwd=”/home/sec”
type=PATH msg=audit(1596148543.861:63): item=0 name=”/usr/bin/whoami” inode=1185 dev=08:02 mode=0100755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL cap_fp=0000000000000000 cap_fi=0000000000000000 cap_fe=0 cap_fver=0
type=PATH msg=audit(1596148543.861:63): item=1 name=”/lib64/ld-linux-x86–64.so.2" inode=131848 dev=08:02 mode=0100755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL cap_fp=0000000000000000 cap_fi=0000000000000000 cap_fe=0 cap_fver=0
type=PROCTITLE msg=audit(1596148543.861:63): proctitle=”whoami”It tells us the success state of the command, parent process id, process id, uid, gid, command, and our custom key (from auditctl -k).
First we have the syscall entry. This logs a syscall call (not meaning to be redundant) with the associated parameters hex encoded (…a0=565156eecbc0…). It gives you the state of the command, process id, parent procces id, user id, group id, command and a custom key if you defined it earlier (keys can be used to identify custom entries you want, you can filter them with auditctl -k). If you wanted to interpret the parameters, as well as translate uid/gid to propper names, you would have to use ausearch with -i. You can invoke it to decode a file with the following syntax:
ausearch -i -if /tmp/fileWe want to decode a line, so we’ll use bash’s handy process substitution (it uses the <(command) syntax and replaces a file with a command’s output)

After that you have the EXECVE type log, which has the parsed arguments for the syscall.
After the EXECVE you have entries for CWD and also the PATH of the invoked command (these are self explanatory).
Lastly, you have the PROCTITLE which as the name suggest, gives you the title of the process being executed (this may or may not match with the command ran, see consideration 2 at the end of the article).
You can find more details on auditd logging in here: https://medium.com/@guruisadog/exploring-audit-daemon-for-threat-hunting-6ef2a30570ad
In order to parse this with ELK, you’ll probably want to forward this log to a centralized log server using your solution of choice (filebeat, wazuh agent, etc..).
For those unaware, ELK is an integrated solution which consists of 3 components. Elastic search (non-relational db), Logstash (a data parser that allows you to normalize or enrich the data) and Kibana (which allows you to visualize the info in a simple matter as well as defining custom dashboards). Warning, I’m only scratching the surface of ELK. If you’re not familiar with it, you should read more at https://logz.io/learn/complete-guide-elk-stack/.
After doing this, you’ll need to write a custom script in logstash in order to parse the command. This is needed because on commands that have multiple arguments, you’ll see a line divided by command arguments. Running “cat test1 test2 test3 test4” will output the following.
type=SYSCALL msg=audit(1596149019.479:174): arch=c000003e syscall=59 success=yes exit=0 a0=562e0acc36c0 a1=562e0ad523c0 a2=562e0ae1df70 a3=8 items=2 ppid=2879 pid=2903 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts2 ses=4 comm=”cat” exe=”/bin/cat” key=(null)
type=EXECVE msg=audit(1596149019.479:174): argc=5 a0=”cat” a1=”test1" a2=”test2" a3=”test3" a4=”test4"Showing commands in this way is not only difficult to read, but more importantly, it makes writing custom regex rules harder. In order to prevent this, we’re going to write a simple ruby script in logstash that will process the EXECVE line and join the command to make it more readable (and also easier to monitor with something like elastalert rules).
def filter(event)
# Getting full log event
full_log = event.get("full_log")
# Making sure its of type EXECVE
command = ""
if /type=EXECVE/.match(full_log) then
log_execve = full_log.split("type=EXECVE")
# Spliting values
log_execve_kv = Hash[log_execve[1].split(" ").map{|x| x.split("=",2)}]
log_execve_kv.each do |key, value|
# If the key equals a followed by 1 or 2 numbers
if /a\d+|a\d+\d+/.match(key) then
# Si value starts with "
if /"/.match(value[0]) then
command += value[1..-2] + " "
else
# Spliting the value in a two by two array
convert = [value].first.scan(/../)
convert.each_with_index { |item, index|
#Substituting 00 by 20
if item == "00"
convert[index] = 20
end
}
outputJoin = convert.join()
output = [outputJoin].pack('H*')
command += output + " "
end
end
end
end
# Save the output in the [command] field
event.set("command", command.chop)
return [event]
endWe save the script in /etc/logstash/audit_commands.rb and the source it in something like /etc/logstash/conf.d/202-filter-custom.conf with
if “auditd” in [decoder][name] {
ruby {path => “/etc/logstash/audit_command.rb”}
}After polishing your Kibana’s queries a bit, you can try to log into a test server and run a test command. In my case, doing an ssh testuser@testserver01 and running “whoami” got me an output similar to this:

A couple of points to keep in mind with this approach:
1) You’re probably gonna want to filter some commands. For example, logging into a bash session through ssh will output about 16 syscalls, and if you’re saving all this output, you can easily fill up a drive when you’re monitoring a considerable number of instances (in this case, over 10k).
When bash initiates an interactive session, it has to perform some commands before giving you a prompt. To give you a practical example, here’s the output for the same instance as the previous picture (testserver01) without filtering. You’re going to want to filter these with a rule.


2) There are some very common commands which are not going to get logged. These are bash built in functions. If you do an “echo test > testfile”, you’re only going to see a call to bash, and no echo. This is due to the fact that bash is not using the default binary (/usr/bin/echo) but rather the built in function. This also happens with the cd command, which doesn’t matter a lot since you’ll see the change in directory in the CWD variable. You can see a list of all bash built in commands here: http://manpages.ubuntu.com/manpages/bionic/man7/bash-builtins.7.html
3) The ruby script only contemplates 100 arguments. Who would run a command with over 100 arguments you ask? Well, when you go into a folder with a lot of files, and you do something like a “ls *.log” to filter them, the wildcard gets expanded into every file ending in *.log before calling ls. If for any reason you need to get the full command, you should contemplate this.
4) You should limit the size of the audit.log file to prevent possible DOS attacks in which an attacker fills up your logging server’s space spamming commands. Don’t forget to set up an alert with this event, so that you dont only prevent these attacks, but also get notified when someone is doing them.
5) The very verbose nature of auditd allows you to get A LOT of output from a simple syscall. This includes, but is not restricted to: auid, uid, gid, euid, suid, current directory, process id, parent process id, etc… This info is easily parsed with logstash default plugins, and gives you a lot of tools to write custom and very detailed alerts. It allows you to get creative.
One example I can give you is a custom rule that we wrote that allows you to identify commands ran from a shell without an associated tty. Why is this useful you ask? Well, if you’ve ever compromised a machine through a service exploit, you’ll know that 90% of the times, you’re gonna get dropped in a really rudimentary shell without an associated tty. This is because this service wasn’t built with the idea of running shells as this user. Our happy hypothetical hacker will usually elevate to a more comfortable shell with python / socat / netcat or any other method that it chooses (https://blog.ropnop.com/upgrading-simple-shells-to-fully-interactive-ttys/). The Phineas Phisher stty magic is my favorite one.
Our custom auditd rule will let you identify this type of events, monitoring the following: first, a command with a service id (typically id < 1000). Second, a command without an associated tty (audit.tty=none). This should trigger one of the most severe alerts that your SOC should have.
As I mentioned before, this method of logging is far from perfect, and it requires some tuning, but after that, you’ll be able to get to the granularity level you choose, without being restricted to the information a third-party tool might give you.
Lastly, this solution involves several technologies which I briefly explained. This is by no means a comprehensive guide. Please see the references listed in order to go deeper on a particular subject.

